nil-migration
(Nearly Instantaneous Live Migration of Virtual Machines, Containers, and Processes)
In Cloud Computing, live migration of virtual machines is an essential aspect of continuous vertical and horizontal expansion or servicing of underlying hypervisor hardware.
The goal of the nil-migration project is to accelerate the rate at which live migration can occur by using CXL technology. The design of nil-migration is such that a VM migration could occur in-between allocated processor slices. When a VCPU uses up its allocated processor slice on the source hypervisor, the next time slice the VCPU receives would be on the target hypervisor. Therefore by design, nil-migration is as instantaneous as multitasking is.
There are two significant aspects of live migration:
- Migrating the running process with its "in-memory" footprint
- Migrating storage or storage connections
The project focus as of this moment is on the first aspect of live migration, migrating the running process with its "in-memory" footprint.
The following is a description of nil-migration using a VM as an example, but nil-migration can also be applied to Containers and Processes
In a traditional hypervisor, we have multiple numa nodes comprised of processors and memory, and in general terms, we want to keep the compute part of the VM on the same numa node as the VMs memory footprint. See picture 1.

Picture 1: Traditional hypervisor
With the addition of CXL memory, we introduce additional numa nodes but unlike the traditional nodes, these nodes are compute-less. The numa nodes are comprised of memory only. See picture 2.

Picture 2: Hypervisor with CXL.mem
The first step of nil-migration is to migrate the VM memory onto one of the compute-less numa nodes. See picture 3.

Picture 3: Hypervisor with CXL.mem
After the first step, we now have the actual VM code execution done on a traditional numa node that includes CPUs. But the memory footprint of the VM is stored on the compute-less CXL.mem device. See picture 4.

Picture 4: Hypervisor with CXL.mem
To expand on the compute-less numa node that CLX provides, the numa node memory is backed by a CXL.mem device, which can be connected to our hypervisor through a CXL switch. See picture 5.

Picture 5: Hypervisor with CXL.mem via CXL switch
Having introduced these new concepts, let's rewind to the first step of nil-migration where we want to de-couple the VM memory from the VM compute. See picture 6.

Picture 6: Hypervisor with CXL.mem via CXL switch
After the de-coupling process, the VM cpu is executed on a traditional numa node, and the VM memory footprint is on the cpu-less numa node. At this point, the VM memory is physically stored on a CXL.mem device connected to our hypervisor through a CXL switch. See picture 7.

Picture 7: Hypervisor with CXL.mem via CXL switch
Let's introduce an additional hypervisor accessing the same CXL.mem device where our VM is, through the same CXL switch. We'll call this new hypervisor the target(T) hypervisor, and the original one we'll call the source(S). See picture 8.

Picture 8: Hypervisors with CXL.mem via CXL switch
The next step of nil-migration is to re-create the compute portion of the VM on the target hypervisor and destroy it on the source. See picture 9.

Picture 9: Hypervisors with CXL.mem via CXL switch
After the step above, the VM is executing on the target hypervisor and the VM memory footprint is on the compute-less numa node backed by the CXL.mem device. See picture 10.

Picture 10: Hypervisors with CXL.mem via CXL switch
At this point, the VM compute and memory are still split between the traditional numa node and the compute-less numa node. We want to merge them back again.
As the final step of nil-migration, we merge the VM compute and memory on the traditional numa node of the target hypervisor. See picture 11

Picture 11: Hypervisors with CXL.mem via CXL switch
Hypervisor Clustering
Another aspect of nil-migration applicability is Hypervisor Clustering, where in case of a crash of hypervisor S, hypervisor T can take over the execution of the VM. See picture 12.
Picture 12: Hypervisors with CXL.mem via CXL switch
Hypervisor clustering could also potentially be used for quasi-real-time CPU load distribution or CPU disaggregation. One hypervisor could be running one set of the VM's virtual CPUs, and a different hypervisor could run another set of virtual CPUs from the same VM.
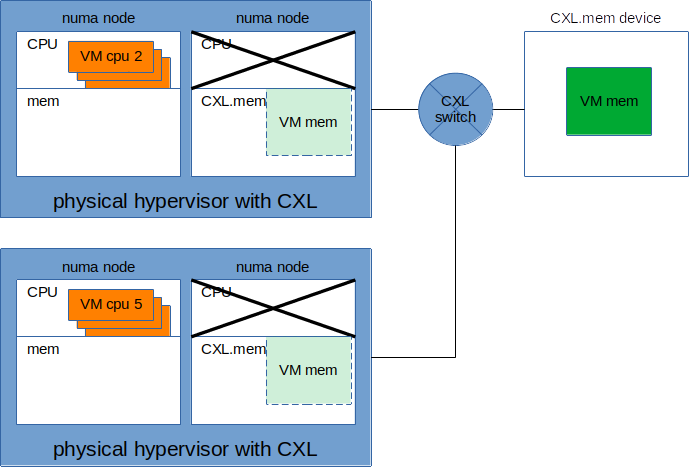
Picture 13: Hypervisors sharing/balancing VM's CPU load.
It's clear from Picture 7, towards the top, that CXL.mem allows disaggregation of memory. But since memory now becomes a discrete component, you are on the flip side disaggregating CPU as well. Because you can dynamically attach more CPU power to this discrete shared memory by adding additional hypervisors, in essence creating a sort of hybrid of both vertical and horizontal expansion. As seen in picture 13.
Talks
LSF/MM/BPF 2023 - BoF VM live migration over CXL memory
Project Status
nil-migration is in its early stages of design/development, all development and prototyping are/will be done using qemu. As of this moment, CXL aspects needed for nil-migration to function are not fully implemented neither in the kernel or qemu.
Help
If you are interested in helping with the development of nil-migration, please subscribe to the mailing list.
Mailing list hosted by lists.linux.dev, repositories hosted by github at github.com/nil-migration